Převod řeči na text nebyl nikdy jednodušší díky modelům převodu řeči na text Hugging Face. Ať už přepisujete rozhovory, generujete titulky nebo vyvíjíte aplikace s umělou inteligencí, Hugging Face poskytuje nejmodernější rozpoznávání řeči poháněné pokročilými modely strojového učení. Nejlepší část? Je vysoce přizpůsobitelný a umožňuje vám doladit modely pro lepší přesnost a výkon na základě vašich konkrétních potřeb.
V této příručce vás provedeme nastavením a používáním rozhraní API Hugging Face pro převod řeči na text , prozkoumejte jeho možnosti přizpůsobení a diskutujte o praktických případech použití. Ale co když potřebujete jednodušší alternativu? Nebojte se – představíme také snadno použitelný nástroj pro převod řeči na text, který tuto práci zvládne bez námahy. Ať už jste vývojář, tvůrce obsahu nebo obchodní profesionál, tato příručka vám pomůže najít nejlepší řešení převodu řeči na text pro váš pracovní postup. Pokračujte ve čtení.
V tomto článku
- Jak funguje objímání řeči obličeje na text
- Nastavení funkce Objímání řeči obličeje na text
- Snazší alternativa:automatický převod řeči na text s Filmora
- Který nástroj je nejlepší
Část 1:Jak funguje objímání řeči obličeje na text
Hugging Face Speech-to-Text je skvělá funkce v knihovně Hugging Face Transformers, která vám umožňuje přeměnit mluvená slova na psaný text pomocí předem trénovaných modelů. K přepisu řeči využívá pokročilou technologii automatického rozpoznávání řeči (ASR). S architekturami založenými na transformátorech, jako je Wav2Vec2, systém zpracovává zvuková data a převádí je na text. A dělá to s velkou přesností.
Jedna z věcí, která umožňuje převod řeči na text v objímání obličeje vyniká jeho integrací do potrubí, která je pro vývojáře velmi snadná. Pomocí několika řádků kódu můžete zpracovávat zvukové soubory a získávat textové přepisy. Má také předem natrénované modely pro více jazyků a řečové scénáře, takže je přizpůsobitelný pro mnoho případů použití.
Proces převodu řeči na text probíhá krok za krokem, aby byl zajištěn přesný přepis:
- Zvukový vstup:Poskytnete zvukový soubor ke zpracování.
- Extrakce funkcí:Systém extrahuje funkce řeči, banky log-mel filtrů. To pomáhá analyzovat zvukové vzorce.
- Odvozování modelu:Předtrénovaný model transformátoru zpracovává funkce a generuje textové tokeny, které představují mluvená slova.
- Textový výstup:Model převede tyto tokeny na textový přepis.
Modely řeči na text Hugging Face, zejména SeamlessM4T-v2, zlepšují efektivitu implementací rámce duální sekvence-sekvence (seq2seq). Obsahuje samostatné kodéry řeči a textu a také HiFi-GAN vokodér, který zlepšuje kvalitu generovaného hlasu. Jedná se o užitečný nástroj pro rozpoznávání a automatizaci řeči s aplikacemi zahrnujícími virtuální asistenty, živé titulky, přepisovací služby a hlasové vyhledávání.
Část 2:Nastavení řeči objímání obličeje na text
Níže je uveden podrobný návod, jak nastavit, aby bylo možné používat řeč při objímání na text:
Krok 1:Vytvořte si účet Hugging Face

První, co potřebujete, je účet na Hugging Face. Vytvořením účtu získáte přístup k předem vyškoleným modelům a rozhraním API. Pokud ještě nemáte účet;
- Přejděte na webovou stránku hugging face
- Klikněte na tlačítko Zaregistrovat se
- Zadejte své údaje a vytvořte si účet
- Po přihlášení přejděte do Nastavení profilu
- Najděte přístupové tokeny a vytvořte nový token (jako úroveň oprávnění vyberte možnost Zápis)
Tento token vám pomůže připojit se k Hugging Face z vašeho kódu.
Krok 2:Nainstalujte požadované knihovny
Další věc, kterou musíte udělat, je nainstalovat všechny knihovny, které budete potřebovat. Chcete-li to provést, otevřete terminál nebo příkazový řádek a zadejte:
pip install transformátory datové sady torchaudio librosa soundfile
Transformers slouží k načítání modelů Hugging Face, torchaudio pomáhá zpracovávat zvuková data, zatímco librosa a soundfile pomáhají načítat a upravovat zvukové soubory.
Krok 3:Načtěte model
Po instalaci všech požadovaných knihoven je další věcí, kterou musíte udělat, načíst model převodu řeči na text. Můžete použít Wav2Vec2, protože je to jeden z nejlépe předem trénovaných modelů pro rozpoznávání řeči.
z transformátorů importujte Wav2Vec2ForCTC, Wav2Vec2Processor
dovozní pochodeň
# Vložte model a procesor
model_name ="facebook/wav2vec2-large-960h"
procesor =Wav2Vec2Processor.from_pretrained(název_modelu)
model =Wav2Vec2ForCTC.from_pretrained(název_modelu)
Krok 4:Převeďte zvuk na text
Zvukový soubor si musíte připravit, aby mu model porozuměl. Chcete-li toho dosáhnout, musíte nahrát zvuk do softwaru. Poté se ujistěte, že je ve správném formátu, aby jej model mohl vhodně zpracovat. Provedete jej modelem a převedete řeč na text.
importovat librosa
#Načtěte zvukový soubor a převeďte jej na 16kHz
def load_audio(cesta_souboru):
audio, sr =librosa.load(cesta_souboru, sr=16000)
vrátit zvuk
audio_file ="example.wav"
audio_input =load_audio(audio_file)
Zpracujte zvukový vstup tak, aby jej model mohl přečíst
input_values =procesor(audio_input, return_tensors="pt", sample_rate=16000).input_values

Poznámka:Pro větší projekty nabízí Hugging Face koncový bod API, který vám umožňuje zpracovávat řeč na dálku bez správy modelu na vašem vlastním zařízení. Jednoduše si zaregistrujte účet Hugging Face, získejte klíč API a odešlete zvukové soubory prostřednictvím jednoduchého požadavku API.
Jak přizpůsobit modely převodu řeči na text
Pokud chcete, aby váš model obličeje Hugging pro převod řeči na text fungoval lépe, musíte jej doladit. Základní model je dobrý, ale nemusí rozumět některým akcentům, hluku na pozadí nebo speciálním slovům. Trénink s vlastními daty mu pomáhá učit se a zlepšovat, takže je mnohem přesnější pro vaše potřeby. Zde je návod, jak můžete model doladit:
- Doladění pomocí vlastních dat:Trénujte model pomocí vlastních zvukových a přepisových datových sad, abyste zlepšili rozpoznávání konkrétních akcentů nebo oborových výrazů.
- Upravit nastavení inference:Upravte parametry, jako je teplota a hledání paprsku, abyste zpřesnili přesnost.
- Přidat vlastní slovní zásobu:Naučte modela nová slova a fráze relevantní pro vaši doménu.
Díky přizpůsobení je model přesnější a spolehlivější pro vaše specifické potřeby. Pokud však dáváte přednost jednoduššímu řešení, podívejte se do další části, kde najdete snadnou alternativu k převodu řeči na text!
Část 3:Jednodušší alternativa:Automatický převod řeči na text s Filmora
Převod řeči na text se zdá příliš komplikovaný a vyžaduje technické dovednosti, jako je kódování. Existuje však jednodušší alternativa_ Wondershare Filmora je mnohem jednodušší přístup k převodu řeči na text. Filmora je populární software pro úpravu videa, který má nástroj pro převod řeči na text, který automaticky přepisuje zvuk pomocí několika kliknutí.
- Filmora vám vše zjednoduší. Nepotřebujete tedy znalosti programování ani složité konfigurace.
- Umí přepsat video řeč na text s přesností až 99 %. Tvůrci obsahu, studenti a dokonce i obchodníci jej tedy mohou použít k rychlému a přesnému generování textu ze zvuku.
- Podporuje více než 45 jazyků a funguje dobře pro video titulky, hlasové poznámky a rozhovory.
- Je vybaven automatickým překladem titulků pro vícejazyčný obsah
- Můžete vygenerovat přizpůsobitelné animované titulky pro zvýšení zapojení
- Vestavěná funkce převodu řeči na text společnosti Filmora také velmi rychle zpracovává zvuková data a šetří čas uživatele. Právě rychlost a schopnost šetřit čas je to, co z něj dělá nejlepší alternativu.
Část 4:Jak používat Filmora Speech-to-Text
Filmora velmi usnadňuje převod řeči na text. Není potřeba vytvářet kód ani nic pracně nastavovat.
Postupujte podle těchto jednoduchých pokynů, abyste svůj přepis okamžitě získali pomocí funkce řeči na text na ploše:
Krok 1:Importujte zvuk nebo video
Otevřete Filmora a přidejte svůj zvukový nebo video soubor. Můžete to udělat jednoduchým přetažením na časovou osu. To vám usnadní práci. Jakmile bude váš soubor na svém místě, jste připraveni pokračovat.
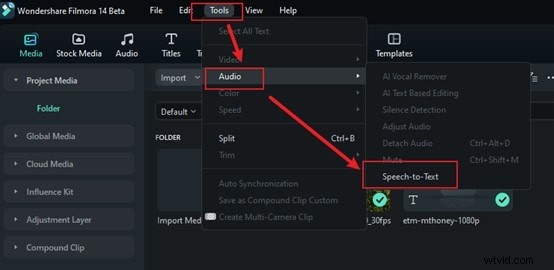
Krok 2:Vyberte možnost Převod řeči na text
Přejděte do nabídky Nástroje v horní liště a klikněte na ni. Chcete-li automaticky analyzovat zvuk, vyberte možnost Zvuk a poté možnost Převod textu na řeč. Není třeba upravovat nastavení ani dělat nic navíc, protože vše zvládne za vás.
Krok 3:Vyberte svůj jazyk
Filmora podporuje mnoho jazyků, takže si vyberte ten, který odpovídá vašemu zvuku. Tento krok je důležitý, protože výběr správného jazyka pomáhá společnosti Filmora přesně přepisovat vaši řeč. Pokud toto přeskočíte, můžete získat nesprávné výsledky.
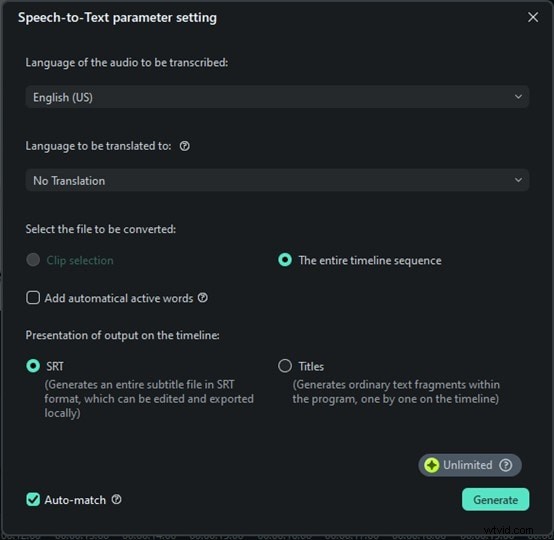
Krok 4:Spusťte přepis a uložení
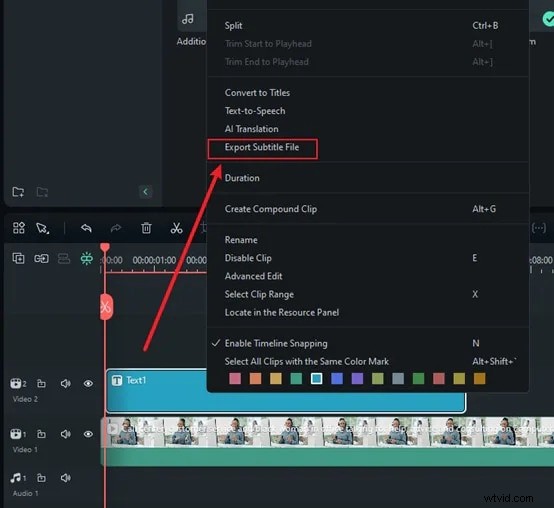
Nyní stačí kliknout na Generovat a Filmora začne přepisovat vaši řeč. Tato část je opravdu rychlá. Během několika sekund uvidíte mluvená slova jako text. Žádné hodiny čekání, žádné složité nastavování, jen okamžité výsledky. Klikněte na textový soubor, vyberte Exportovat přepis souboru titulků a uložte jej a přidejte jej jako titulky k videu.
Pokud chcete převést video řeč na textové titulky, Filmora nabízí ve své mobilní aplikaci také funkci AI Captioning. Umožňuje vám generovat textové titulky na vašem mobilním zařízení za méně než minutu
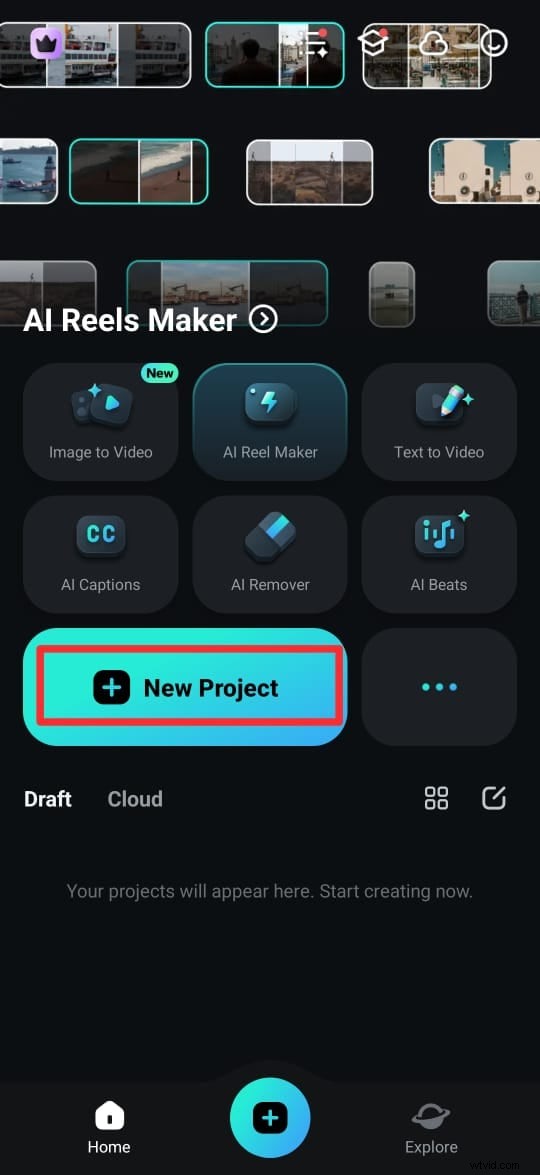
Krok 1:Stáhněte si aplikaci Filmora z obchodu Google Play (Android) nebo App Store (iPhone). Můžete jej také získat z oficiálních stránek. Po instalaci otevřete aplikaci a klepněte na Nový projekt.
Krok 2. Vyberte video z knihovny médií a klepnutím na Importovat je přidejte do svého pracovního prostoru.

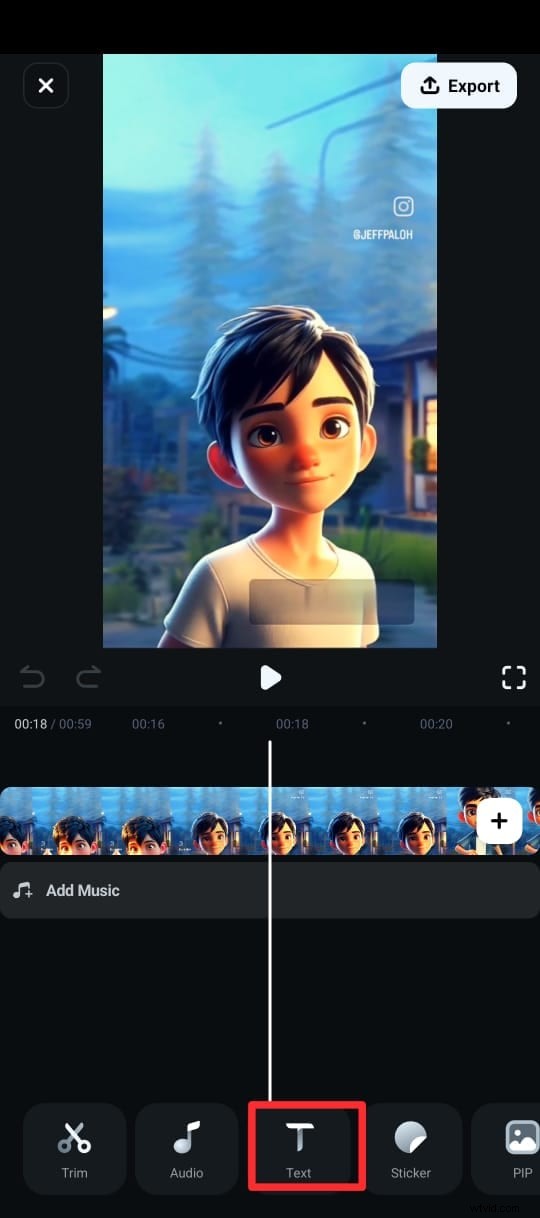
Krok 3:V dolní nabídce klepněte na Text (označený ikonou T) a vyberte AI Captions.
Krok 4:Na další obrazovce vyberte jazyk, zapněte volbu Detekce reproduktoru a klepnutím na Přidat titulky vygenerujte text z řeči videa.
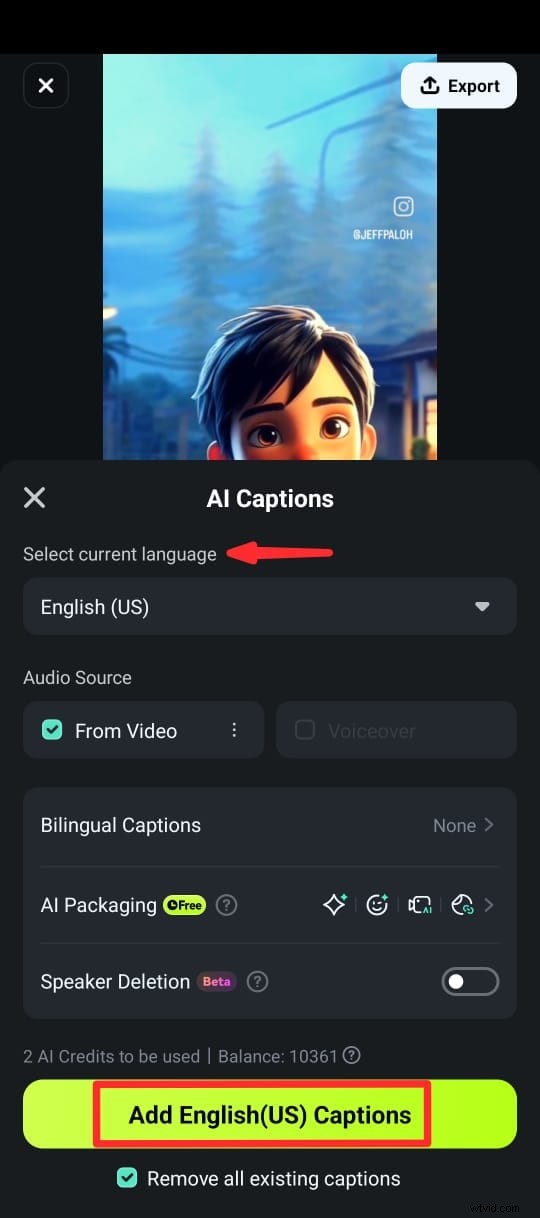
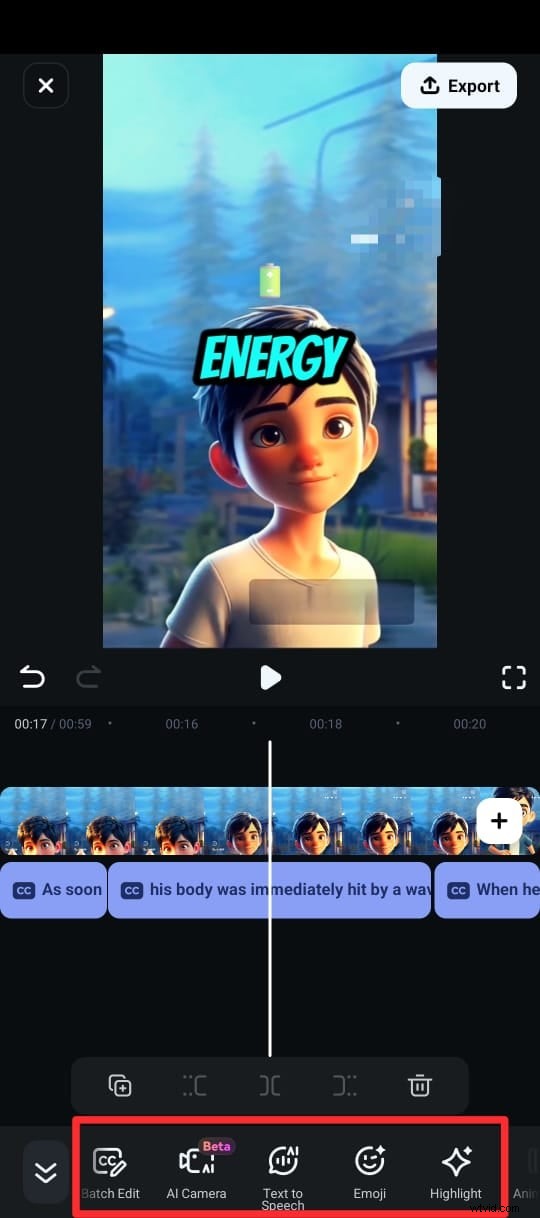
Krok 5:Po vygenerování titulků můžete upravit text pomocí různých textových šablon, emotikonů a písem. Můžete také upravit text klipu na časové ose výběrem možnosti Upravit řeč v sadě úprav.
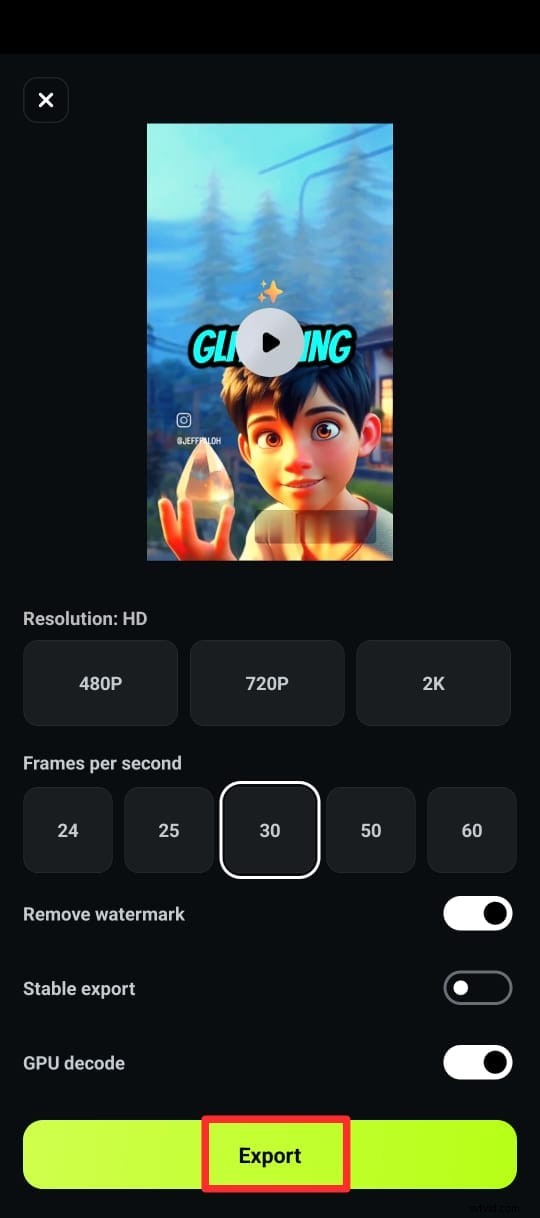
Krok 6:Exportujte své video s titulky v požadovaném formátu.
Část 5. Který nástroj je nejlepší?
Výběr mezi Hugging Face a Filmora závisí na vašich konkrétních potřebách a úrovni technických znalostí. Každý nástroj slouží k jinému účelu, takže pojďme prozkoumat, který z nich je pro vás ten pravý, na základě různých scénářů.
- Pokud potřebujete pokročilé přizpůsobení a ovládání pomocí umělé inteligence, je lepší volbou řeč Hugging Face na text. Je ideální pro vývojáře, výzkumníky a profesionály, kteří chtějí trénovat modely, dolaďovat parametry a pracovat s velkými datovými sadami. Vyžaduje však znalosti kódování a čas na nastavení, takže je méně vhodný pro začátečníky nebo ty, kteří hledají rychlé řešení.
- Na druhou stranu, pokud chcete rychlý a přesný přepisový nástroj bez jakéhokoli technického nastavení, Filmora je ta správná cesta. Je určen pro tvůrce obsahu, studenty a profesionály, kteří potřebují jednoduché řešení na jedno kliknutí.
- Použijte Filmora, pokud přidáváte titulky/titulky do videí, přepisujete přednášky nebo převádíte řeč na text pro zprávy.
- Těm, kteří pracují ve specializovaných oborech, které vyžadují rozpoznávání řeči specifické pro doménu, vám Hugging Face umožňuje trénovat model na terminologii specifické pro dané odvětví. To zajišťuje lepší přesnost pro složitý žargon, ale opět to vyžaduje úsilí a technické know-how.
- Pokud je vaším hlavním cílem přepis videoobsahu, je Filmora pohodlnější možností, protože rychle převádí řeč na text, takže je ideální pro youtubery, podcastery a tvůrce sociálních sítí.
Stručně řečeno, pokud máte rádi kódování a chcete plnou kontrolu a přizpůsobení, přejděte na převod textu na řeč v huggingface. Ale pokud chcete snadný a okamžitý přepisový nástroj, Filmora je perfektní volbou. Vyberte si ten, který nejlépe odpovídá vašemu pracovnímu postupu a úrovni dovedností.
Závěr
Převod řeči na text nemusí být složitý. Převod textu na řeč pomocí obličeje je výkonný nástroj, ale vyžaduje kódování a nastavení, což je pro vývojáře skvělé. Pokud však chcete něco rychlého a snadného, Filmora je nejlepší alternativou. Pouhými několika kliknutími můžete přepisovat zvuk bez námahy; žádné kódování, žádný stres. Proč trávit hodiny složitým nastavením? Vyzkoušejte funkci převodu řeči na text společnosti Filmora ještě dnes a převeďte svůj zvuk na text během několika sekund